





从”人工收集竞品动态”到”自动发现业务信号”
这次实践要解决的是:竞品变化如何被持续发现、准确理解。场景是日常工作竞品情报周报,强调定期汇总、风险分级和行动建议。
传统方式
- 人工搜索新闻、官网、应用商店和社区
- 靠截图、复制链接、手动整理 PPT
- 持续占用大量时间,低效且无成长性
- 结论常停留在“感觉竞品在调整”
自动化目标
- 自动采集多市场、多竞品、多数据源
- 用 Diff 和 AI 判断变化是否重要
- 输出红黄绿风险和对应行动项
- 让周报成为决策入口,而不是资料堆积
竞品更变通知
关注“哪些页面、规则、费率或政策发生了变化”,并把变化同步给对应负责人。
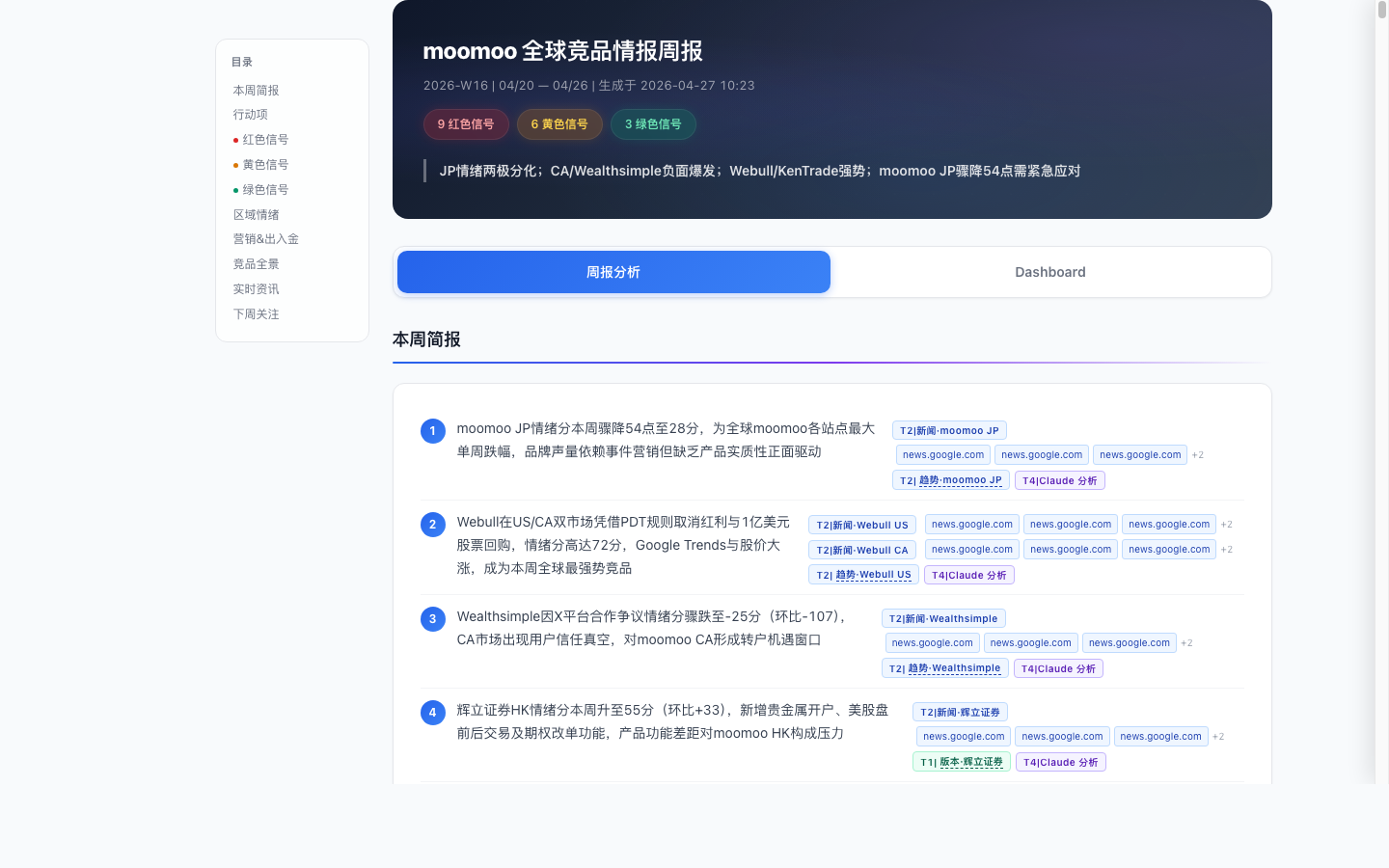
竞品情报周报
关注“本周哪些竞品动作最值得看”,并形成市场、产品、运营可读的摘要。
行动建议
关注“我们应该怎么响应”,把事实、判断和下一步动作放在同一条信号里。
从人工资料整理到自动化交付
目前已经证明了从需求定义、过程数据库、飞书周报到线上 Dashboard 的链路可以跑通,并能把竞品信息整理成业务可读的周报形态。
从可运行系统到业务效果闭环
后续还需要继续验证 AI 判断准确率、是否发现人工会漏掉的真实信号,以及周报是否被业务团队长期使用。
四层架构 + Claude Code 委派式协作
实现路径先搭建端到端工作流:采集、存储、分析、输出。Claude Code 负责把目标拆成可运行模块,PM 负责定义竞品范围、业务口径和验收标准。
采集层 — 多源数据入口
存储层 — 结构化沉淀
分析层 — CLAUDE 智能处理
输出层 — 三种最终交付
Claude Code 的差异点
普通聊天式工具更像问答助手,擅长解释、润色和生成片段;Claude Code 更像可以进入项目环境的执行型 Agent。它能读文件、改代码、跑命令、看报错、修复问题,并把结果重新交付。
对 PM 来说,交互方式从“问 AI 怎么做”变成“把目标和约束委派给 AI”。
PM 的核心价值不是写代码,而是判断该监控什么、数据口径是否正确、最终产出是否可用于决策。
# 委派式协作示例 PM: 做一个出入金规则变化监控,写入 Bitable AI: 设计采集器、快照、Diff、字段结构并实现 PM: 入金来源口径改为 Bank AI: 定位引用、统一修改、重新生成页面 PM: 营销变化也放进周报 AI: 新增采集器、输出模块和展示区块
最终版:竞品情报周报与 Dashboard
最终版要证明的不是“AI 已经替代业务判断”,而是竞品情报周报可以从人工整理推进为一条可运行、可追踪、可持续更新的自动化工作流。当前已经有 8 个市场、50+ 家竞品清单、过程数据库、数据源与采集频率说明、飞书周报和线上 Dashboard 作为证据;尚未完全证明的是 AI 判断准确率、人工漏检信号发现能力,以及周报进入团队真实决策后的业务闭环。
3.1.1 方案介绍
方案核心是建立“竞品情报自动化闭环”:先定义市场和竞品清单,再接入不同类型的数据源,随后用 AI 将非结构化内容转成结构化信号,最后用可读、可演示、可追踪的形式输出。当前已经解决的是自动化交付链路,后续重点是把信号准确率和业务使用情况继续验证出来。
3.1.2 具体描述及实现情况
红黄绿判断标准
信号不是只看 AI 结论,而是结合影响范围、紧急度、竞品强度和证据可信度进行分级。T1/T2/T3/T4 数据可信度用于提醒读者哪些来自官方或聚合来源,哪些仍需要人工核实。
涉及市场、用户群、产品模块和潜在业务影响。
是否需要本周响应,是否会影响近期运营节奏。
竞品动作是否具备规模、传播声量或产品差异。
优先看官方、聚合数据和可追溯来源,AI 判断需要标注边界。
红色信号:PDT 松绑与活跃交易用户争夺
判断逻辑:影响范围较大、紧急度较高、竞品强度明显,因此被放入红色信号。当前结论可用于演示信号生成方式,后续仍需用业务反馈验证响应效果。
黄色信号:SG / CA / AU 本地化竞争升温
判断逻辑:多个区域出现功能、费率、内容传播和用户情绪变化,但紧急度低于红色信号,适合作为周报中的持续观察项。
绿色信号:MY 情绪稳健与 AI 功能传播模板
判断逻辑:正向市场表现和可复用传播模板可以沉淀为参考案例,但是否能跨市场复用,还需要后续运营数据验证。
两种输出形态
- 飞书文档周报 — 每周一自动生成,包含执行摘要、红黄绿信号、行动建议,适合邮件转发和评审会阅读
- 线上 Dashboard — 实时查看评分趋势、版本更新、出入金规则、营销动态,支持按竞品和区域筛选
数据可信度分级
每条信号标注数据来源等级,帮助读者判断结论可靠程度:
已经可以证明的问题
- 覆盖范围:8 个市场,50+ 家竞品清单见需求文档。
- 数据底座:过程数据库可以验证采集字段、数据源和采集频率。
- 自动化交付:飞书周报和线上 Dashboard 已发布,当前可持续运营和更新。
- 效率收益:当前估算每周节省约 2 小时人工整理时间。
还不能直接下结论的问题
- 漏检信号:暂无人工会漏掉的真实信号案例,需要继续追踪。
- AI 准确率:需要进一步人工抽检,不能直接声称准确。
- 业务使用:暂无团队真实推广应用结果,需要后续验证。
- 决策闭环:是否推动业务动作和结果改善,还需要持续运营数据支撑。
从最小闭环到可分享系统
实现过程采用增量式策略:先用需求文档明确目标、范围,再用数据采集文档沉淀字段、竞品和数据源,最后通过飞书周报和 Dashboard 被业务直接阅读。这个过程本身形成了一条证据链:需求文档证明范围,过程数据库证明采集,飞书周报证明业务表达,线上 Dashboard 证明发布和持续运营。
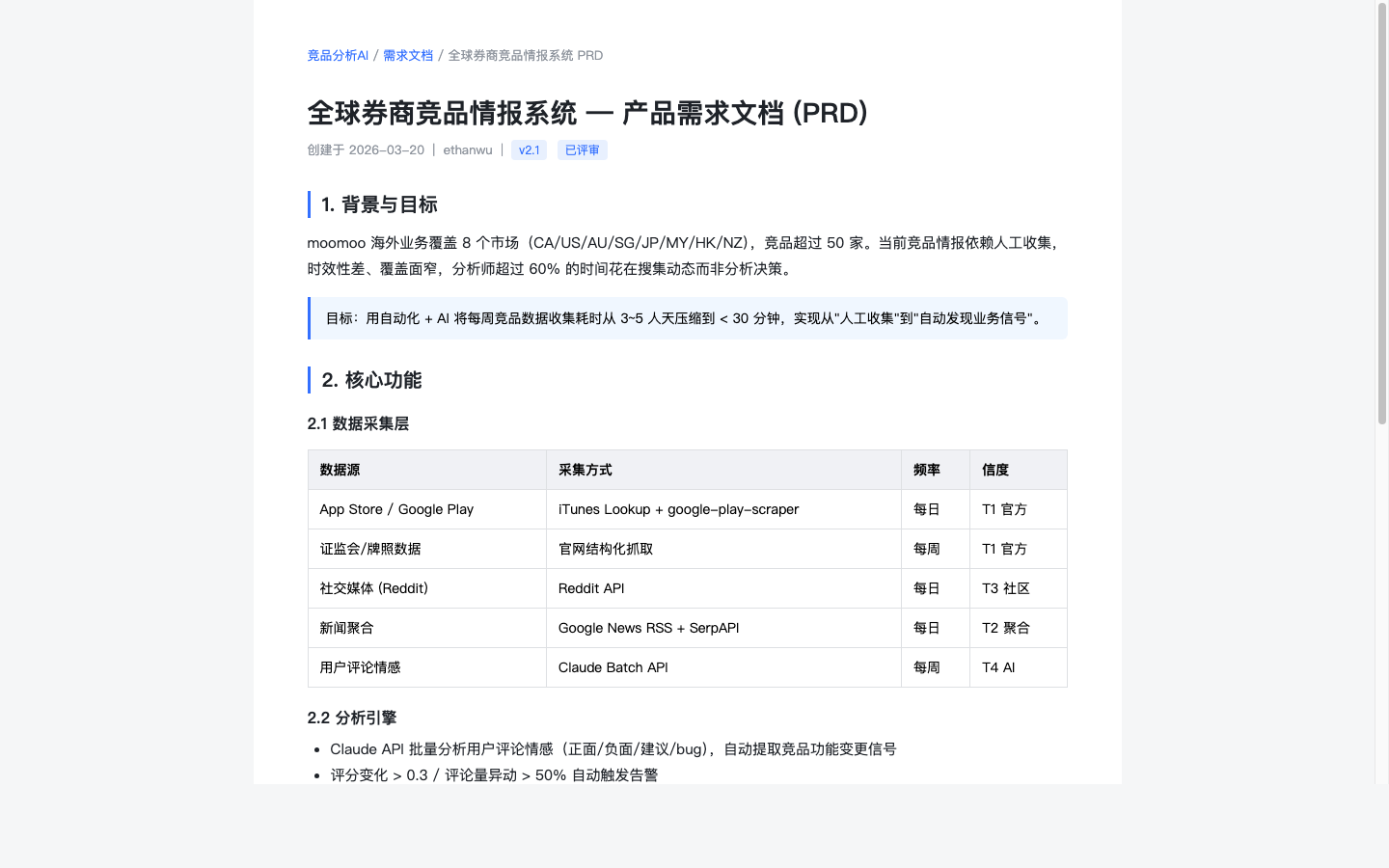
过程材料 1:需求文档
定义竞品情报系统要解决的问题、覆盖范围、最终产出,是整个项目的起点。
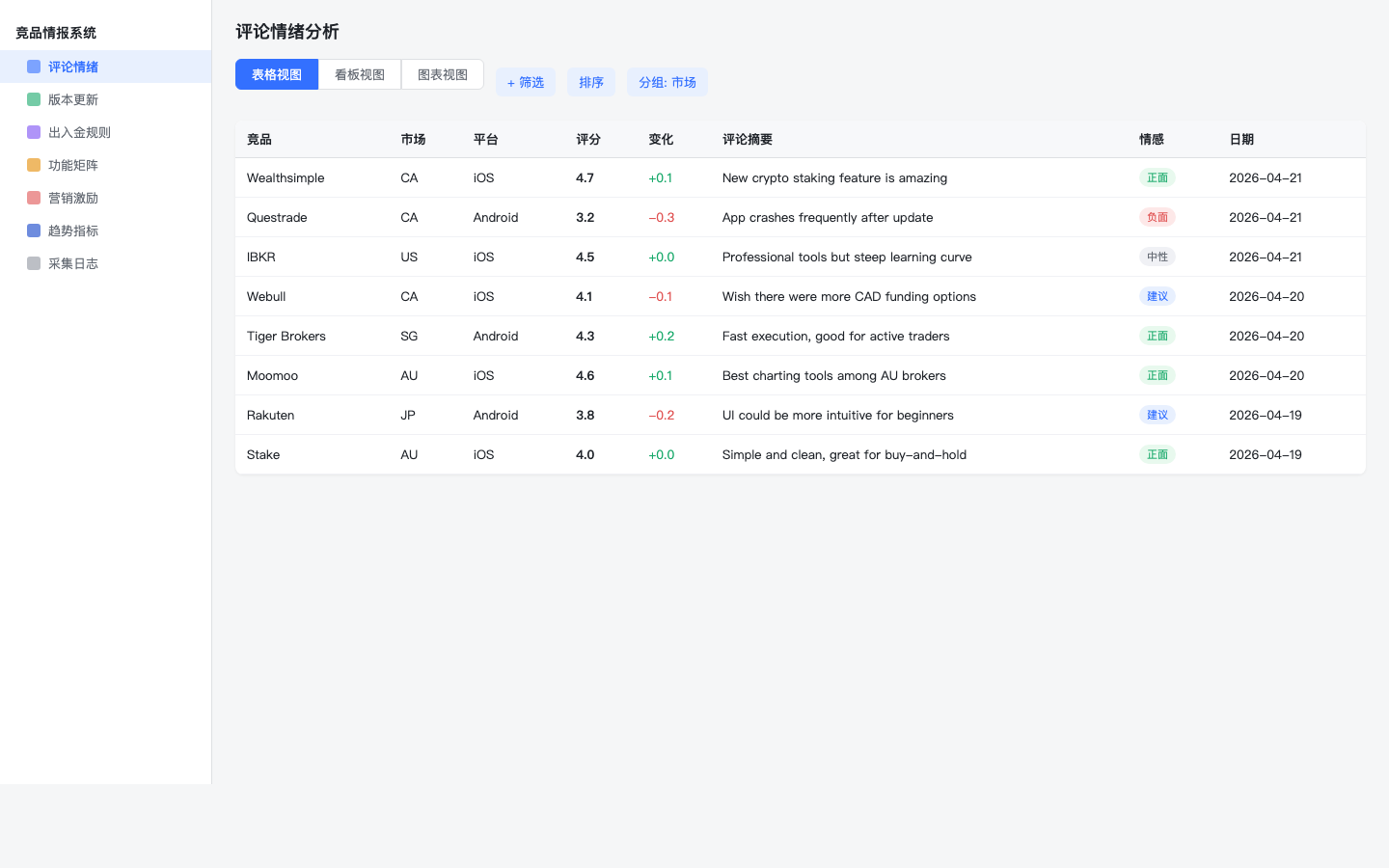
过程材料 2:数据采集文档
沉淀竞品清单、数据源、采集字段和结构化表,承接从业务口径到数据底座的转换。
过程材料 3:飞书周报文档
展示自动化输出如何转化为业务可读内容,包括本周简报、红黄绿信号和行动项。
需求文档:明确目标与验收标准
先把业务问题写清楚:要监控哪些市场和竞品、最终输出给谁看、什么样的信号算有价值。50+ 家竞品清单和 8 个市场范围在这里形成依据。
数据采集文档:搭建竞品数据底座
围绕竞品清单、数据源、字段和采集频率建立 Bitable 结构,支撑后续新闻、评分、趋势、股价和官网规则采集。每个市场和竞品是否采集,可以回到过程数据库核验。
Claude 分析能力集成
加入情绪评分、页面变化检测、结构化提取和信号分级。红黄绿判断采用影响范围、紧急度、竞品强度和证据可信度四个维度。
飞书周报到 HTML / Dashboard
先用飞书周报验证业务表达,再扩展为 HTML 演示版和 Cloudflare Pages 线上看板。当前已经发布部署到网络,并进入持续运营和更新。
真实踩过的坑
做竞品情报自动化不是"让 AI 写几段代码"就能跑通的事。以下是我们在实践中真实遇到的问题,每个坑背后都有一条可复用的经验。
踩坑实录
小红书爬虫被平台警告
尝试爬取小红书竞品相关笔记和评论,触发反爬机制,账号收到平台风控警告。社交媒体平台对爬虫行为零容忍,轻则限流、重则封号甚至法律追责。
教训:社交平台数据不要碰爬虫。优先用官方 API、RSS、或人工定期摘录。竞品情报不值得承担合规风险。
高质量数据源都要付费
Sensor Tower、SimilarWeb、data.ai 等专业竞品数据平台都需要企业级订阅(年费数万美元起),免费替代方案的数据粒度和准确性差距非常大。
教训:接受免费数据的局限性,用"评分变化 + 评论量增量"近似下载趋势,标注数据可信度等级(T1-T4),而不是假装数据很准。
AI 分析会"编造"竞品动态
当输入数据不足时,Claude 会基于训练知识补充看似合理但无法验证的竞品信息,比如编造功能上线时间、费率调整细节。如果不加校验直接发到周报里,会严重损害可信度。
教训:AI 分析结果必须和原始数据交叉验证。Prompt 中加"如果数据不足,请明确说明而不是推测",输出里标注"来源 / AI 推断"。
免费 API 突然变更或限流
Google Play 评论接口经常超时;iTunes Lookup API 偶尔返回格式变化;Google News RSS 某些地区的结果为空。任何免费数据源都不保证 SLA。
教训:采集器必须有容错和重试机制。每次采集记录成功/失败日志,失败不要阻断整条 pipeline,而是在报告中标注"本期数据缺失"。
竞品官网加了反爬防护
出入金规则页、费率页等关键页面部分竞品加了 Cloudflare WAF 或动态渲染,静态 requests 抓取拿到的是空白页或验证码页面。
教训:对于反爬强的页面,改用定期人工快照 + MD5 对比的方式。不必所有数据都自动化,关键是"变化能被发现"。
部分市场数据源极度稀缺
马来西亚、泰国等新兴市场的英文新闻和社区讨论极少,Google Trends 数据波动大、样本不足,导致这些市场的信号覆盖远不如美国、新加坡。
教训:坦诚标注覆盖差异,不要为了"8 个市场全覆盖"而硬凑低质量数据。对数据稀缺市场,采用本地语言源 + 人工补充的混合策略。
AI 负责执行,PM 进行判断
AI 真正提高效率的地方,是把一个模糊业务想法推进成可运行系统。这个项目也提醒我:可运行不等于已产生业务价值,最终仍要回到证据、准确率和真实使用场景。
但"这个信号重不重要",仍然需要人来判断。
PM 的核心能力正在从执行速度转向问题定义、质量判断和业务品味。
PM 不再只写需求
更重要的是定义目标、约束、口径和验收标准。
AI 不只是生成内容
它可以承担工程执行、排错和重复迭代。
真正的难点仍是判断
哪些信号重要、哪些结论可用,哪些还需要人工核实,仍需要业务经验把关。